Index
PostgreSQL🔗
Resources🔗
Notes🔗
Setup on MacOS🔗
NOTE : remove any already existing installation of postgresql.
Visit Postgres.app and download the app.
After that download PG Admin 4 , a web based tool to manage and inspect a Posters database. Can connect to local or remote server.
- Open Postgres.app connect/initialize a database
- Open PGAdmin 4 and in server -> register
- set general name as localhost
- set connection address localhost
- set username as local mac username (for mac
whoami)
PostgresSQL Complex Datatypes🔗
Data Types Available : Numbers, Date/Time, Geometric, boolean, Currency, Character, Range, XML, Binary, JSON, Arrays, UUID.
Type Number can many types : smallint, integer, bigint, small serial, serial, big serial, decimal, numeric, real, double precision, float.
Type Character : CHAR (5), VARCHAR, VARCHAR(40), TEXT
Boolean Type : TRUE (true, yes, on, 1, t, y) , FALSE(false, no, off, 0, f, n), NULL.
Date Type : Date, Time, Time with Time Zone, Timestamps, Interval
Database-Side Validation Constraints🔗
We usually create validation at a web-server level/interface and ensure integrity of data. For example if someonw inserts an item with negative price, certainly its implying we are going to pay the user.
PGAdmin 4 directly connects to table there is no validation web server present. So whatever we execute is going to happen in the database. We could add validation at a database level.
Create a new database in PGAdmin4 with name validation. Right select validation and select Query tool.
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR (40),
department VARCHAR(40),
price INTEGER NOT NULL,
weight INTEGER
);
INSERT INTO products (name,department,price,weight)
VALUES
('Shirt','Clothes','20','1');
Certainly we could also try to put NULL in the INSERT.
To implement some level of validation we can use NOT NULL Keyword to the database. If you already created the table and want to update the table.
NOTE : If this price already have some null value you have to remove it before applying new constraint otherwise alter table won’t work.
Alternatively we can update all null values to some value 99999 and then apply ALTER.
Default Column Values
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR (40) NOT NULL,
department VARCHAR(40) NOT NULL,
price INTEGER DEFAULT 9999,
weight INTEGER
);
Uniqueness Constraint
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR (40) NOT NULL UNIQUE,
department VARCHAR(40) NOT NULL,
price INTEGER DEFAULT 9999,
weight INTEGER
);
Again you can’t apply unique constraint unless you clean up all duplicate values. To remove constraints you can use ALTER TABLE.
Validation Check
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR (40) NOT NULL UNIQUE,
department VARCHAR(40) NOT NULL,
price INTEGER CHECK (price > 0),
weight INTEGER CHECK (weight > 10)
);
Checking multiple columns
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
name VARCHAR(40) NOT NULL,
created_at TIMESTAMP NOT NULL,
est_delivery TIMESTAMP NOT NULL,
CHECK (created_at < est_delivery)
);
If you have a webserver like nodejs or golang, where should we add validation ?
Generally use spread validation everywhere :)
You get 2 very important benifits
- We are certain that data is always correct when inside table.
- If say some data does get through web server and reaches the Database and database takes care of data.
Database Design Patterns🔗
Working with Many Tables requires schema designer, its easy and nice to document db structure. Few examples are dbdiagram.io, drawsql.app, sqldm.com, quickdatabasediagrams, ondras.zarovi.cz/sql/demo. Last one is an open source and quite good schema designer.
Instagram Database Design.
Design Like System🔗
We want to implement a like system.
Rules
- Each user can like a specific post a single time
- A user should be able
unlikea post - Need to be able to figure out how many users like a given post
- Need to be able to who likes a given post.
- Something aside a post like comments can be liked as well
- Keep track of dislike or reactions system
DO NOT
- Adding a ‘likes’ columns to Posts
DO
- Add a third table likes which has 2 columns such that it will relate user_id with post_id
- Add a unique constraint to (user_id, post_id) -> one player only likes one post.
Polymorphic Association
Not recommended but they are still in use. We will have a likes table with column id, user_id, liked_id, liked_type (posts, comments).
But there is an issue with above approach, user_id is consistently checked by postgres at insertion to make sure the user with inserted id exists. But in case of liked_id there is no such consistency check.
An alternative design using polymorphic association
So we will now change likes table to have id, user_id, post_id, comment_id such that only one row at a time will have either set post_id or comment_id.
CHECK (
COALESCE ((post_id)::BOOLEAN::INTEGER, 0) +
COALESCE((comment_id)::BOOLEAN::INTEGER,0)) = 1;
Another solution we will create 2 tables posts_likes and comments_like and separate likes :) Only downside is we will have to create like for each new thing, but good thing is the consistency constraints.
Building a Mention System🔗
Additional Features that are caption to post and adding location of the photo, we can also tagging people in the post.
Caption and location are obvious and easy to add but tagging the photo will require us to create a new table with id, user_id, post_id, x, y (for location of tag on the photo).
What about tags on caption ? we could set both x and y as null and it will represent tags inside caption or we can create new table which is called tags_caption, both solution are equally good.
Usually deciding factor is that if we are running too many queries for tags in caption then we should break into new tables.
Building a HashTag System🔗
Hashtags are present in comments, posts, captions, users bio. We can certainly break it into 3 hashtag tables for each type.
But if generally notice the usage of hashtag which is in search feature, and there it is only searched across captions only so we can certainly get away with one hashtag table.
For performance reasons we cannot store every hashtag into the same hashtags table, we will split up and create a table with id, hashtag_id(foreign key), post_id where hashtag_id links id to title of tags in another separate table.
Adding more user data🔗
We can add few more details about user, we can add Biography column, avatar url, phone number, emails , password (hashed), status (online/active/recently).
Why no posts, followers, following ?? We could certainly store them as simple numbers. But we can easily query of number of posts, and followers :). This concept is called as derived data and generally we dont’ store it unless its costly or difficult write query out.
We can create a simple table for followers id, user_id, follower_id with constraints like user never follows himself and can’t follow a person more than once.
Implementing Database Design Patterns🔗
Now course of action is realisation of above explained database design. Create a new db using PGAdmin. Open up the Query Tool and insert following Table creation.
CREATE TABLE users (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
username VARCHAR(30) NOT NULL,
bio VARCHAR(400),
avatar VARCHAR(200),
phone VARCHAR(25),
email VARCHAR(40),
password VARCHAR(50),
status VARCHAR(15),
CHECK(COALESCE(phone, email) IS NOT NULL)
);
CREATE TABLE posts(
id SERIAL PRIMARY KEY,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
url VARCHAR(200) NOT NULL,
caption VARCHAR(240),
lat REAL CHECK(lat IS NULL OR (lat >= -90 AND lat <= 90)),
lng REAL CHECK(lng IS NULL OR (lng >= -180 AND lng <= 180)),
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE
);
CREATE TABLE comments (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
contents VARCHAR(240) NOT NULL,
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
post_id INTEGER NOT NULL REFERENCES posts(id) ON DELETE CASCADE
);
CREATE TABLE likes (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
-- polymorphic association
post_id INTEGER REFERENCES posts(id) ON DELETE CASCADE,
comment_id INTEGER REFERENCES comments(id) ON DELETE CASCADE,
-- either post or comments id defined, not both and not none (xor)
CHECK(
COALESCE((post_id)::BOOLEAN::INTEGER,0)
+
COALESCE((comment_id)::BOOLEAN::INTEGER,0)
= 1
),
UNIQUE(user_id, post_id, comment_id)
);
CREATE TABLE photo_tags (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
post_id INTEGER NOT NULL REFERENCES posts(id) ON DELETE CASCADE,
x INTEGER NOT NULL,
y INTEGER NOT NULL,
UNIQUE(user_id, post_id)
);
CREATE TABLE caption_tags (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
post_id INTEGER NOT NULL REFERENCES posts(id) ON DELETE CASCADE,
UNIQUE(user_id, post_id)
);
CREATE TABLE hashtags (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
title VARCHAR(20) NOT NULL UNIQUE
);
CREATE TABLE hashtags_posts (
id SERIAL PRIMARY KEY,
hashtag_id INTEGER NOT NULL REFERENCES hashtags(id) ON DELETE CASCADE,
post_id INTEGER NOT NULL REFERENCES posts(id) ON DELETE CASCADE,
UNIQUE(hashtag_id, post_id)
);
CREATE TABLE followers (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
leader_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
follower_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
UNIQUE(leader_id, follower_id)
);
Inserting Fake Data
Download this data Link
Right click database on PGAdmin 4 and restore. Then locate the file and select these 4 restore option : Only data, owner, Single Transaction, Trigger, verbose messages
Some execises
- Find the 3 users with highest id number
- join users and posts table show the username of user id 200 and captions of all the post they created.
- Show each username and the number of
likesthat they have created.
Internals of PostgreSQL🔗
Where Does Postgres Store Data ?🔗
SHOW data_directory; shows directory where postgres is storing data.
To see the folder where our database is stored.
If you see the corresponding folder you see a lots of file but why so many files ? To see the usage of all objects execute
Heaps, Blocks, and Tuples🔗
Heap File : File that contains all the data about (rows) of our table.
Tuple or Item : Individual row from the table
Block or Page : The heap file is divided into different # of pages/blocks. 8k large.
Refer to this link for more details Link.
A Look at Indexes for performance🔗
Steps that happen when u execute the query.
- Postgresql loads up heap file on RAM
- Full Table scan ( PG has to load many (or all) rows from the heap file to memory).
- Index : Data Structure that efficiently tells us what block/index a record is stored. Helps improve performance and remove the need of Full table scan.
Extract only the property we want to do fast lookup by and the block/index for each. To further improve performance for searching we can sort those indexes in some meaningful way. Usually we organize data into a tree data structure that evenly distributes the values in the leaf nodes.
Creating an Index for username table
To benchmark a query try running following query after and before creating index
Downside of Indexes🔗
For all index data there is a map storage is being utilised to house that index. For printing size of a table.
- can be large
- expensive and slow insert/update/down - the index has to be updated
- index might not actually get used !
Types of Index
By default postgresql uses BTree Indexes, others are Hash, GiST, SP-GiST, GIN, BRIN.
Automatically Generated Indexes🔗
Postgres by default creates indexes for
- primary keys
- Unique keys
These are not listed under ‘indexes’ in PGAdmin ! To check you can execure the following query.
Query Tuning🔗
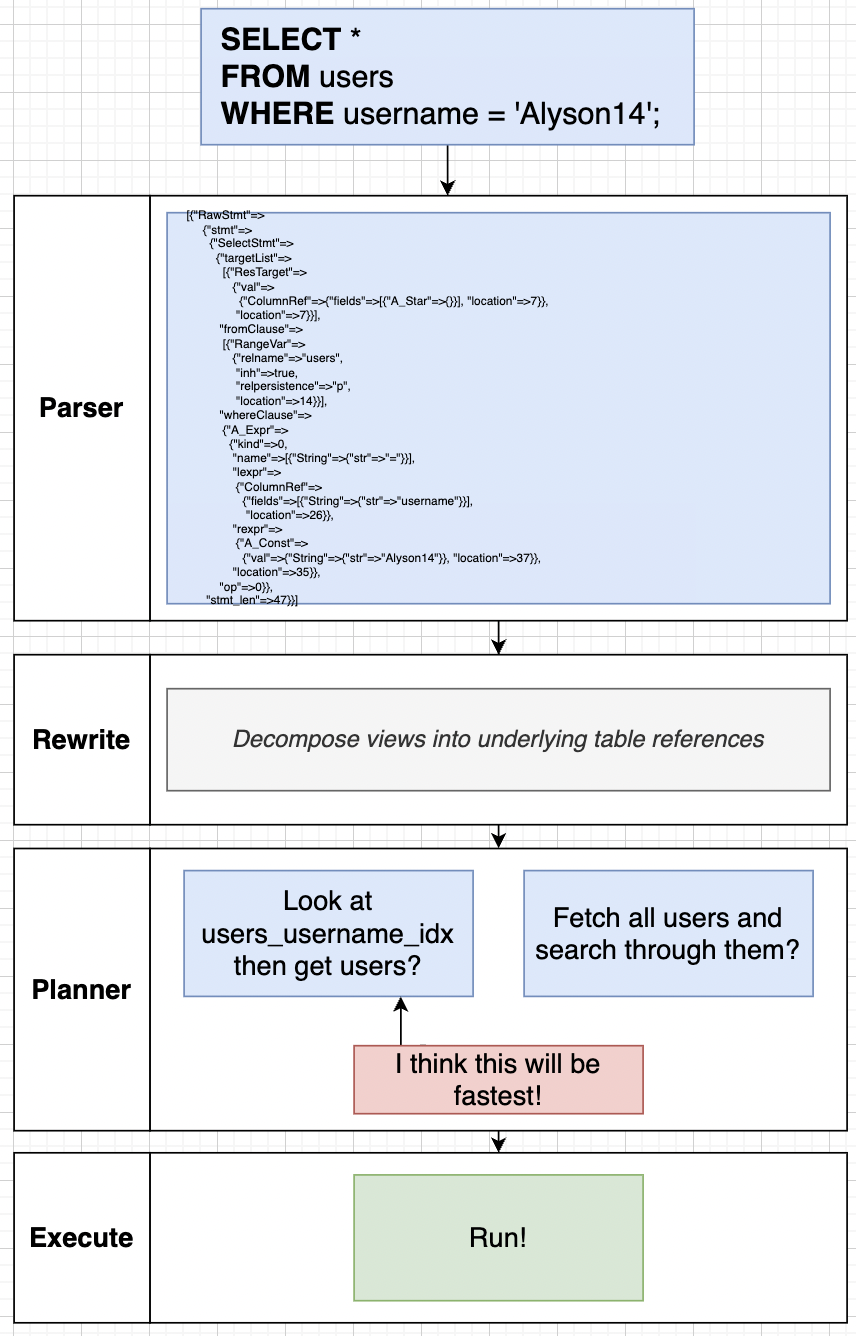
Query we write goes to a Parser, Rewriter, Planner and then Executer.
Parser : processing of query, mostly validation and then creates query tree.
Rewriter : decompose views into underlying table references.
Planner : look at various plans and chooses most efficient plan. (this is point of optimisation )
Executer : actually runs the query !!
Planner Step :🔗
EXPLAIN : Build a query plan and display information about it.
EXPLAIN ANALYZE : Build a query plan, run it, and info about it.
Never use these in production.
EXPLAIN SELECT username, contents
FROM users
JOIN comments ON comments.user_id = users.id
WHERE username = 'Alyson14';
There is also a explain analyze builtin PGAdmin.
Every Query Node has a cost associated with it. Query Planner is able to execute and plan because it has information about the table.
Cost : Amount of time to execute some part of our query plan.
Note : Loading data from random spots off a hard drive usually takes more time than loading data sequentially. So indexes use random fetch of maybe 2 pages while direct searching is doing fetch of 100 pages sequentially. So it may seem quantity wise that indexes are more efficient but random fetch comes with its own penalty.
a row costs like 1 % of the how much 1 page costs.
To get more details about costs of different factors while runtime query use this link
Again planner decides the best course of action for the query we execute :)
Common Table Expression🔗
A simple way to write sql queries more clearly.
Ques : Show the username of users who were tagged in a caption or photo before Jan 7th, 2010.
A simple option is take union of boths tags tables and then do join on username.
SELECT username, tags.created_at
FROM users
JOIN (
SELECT user_id, created_at FROM caption_tags
UNION ALL
SELECT user_id, created_at FROM photo_tags
) AS tags ON tags.user_id = users.id
WHERE tags.created_at < '2010-01-07';
CTE Format.
WITH tags AS (
SELECT user_id, created_at FROM caption_tags
UNION ALL
SELECT user_id, created_at FROM photo_tags
)
SELECT username, tags.created_at
FROM users
JOIN tags AS tags ON tags.user_id = users.id
WHERE tags.created_at < '2010-01-07';
Recursive CTEs🔗
Useful anytime we have a tree or graph data structure. Must use a ‘union’ keyword. Its very very challanging concept.
WITH RECURSIVE countdown(val) AS (
SELECT 10 AS val -- Intial, Non-recursive query
UNION
SELECT val-1 FROM countdown WHERE val > 1 -- recursive query
)
SELECT *
FROM countdown;
Ques - find the 2-3 degree contacts in our instagram app
WITH RECURSIVE suggestions(leader_id, follower_id, depth) (
SELECT leader_id, follower_id, 1 AS depth
FROM follwers
WHERE follower_id = 1000
UNION
SELECT follower.leader_id, follwers.follower_id, depth+1
from followers
JOIN suggestions ON suggesions.leader_id = follwers.follower_id
WHERE depth < 3
)
SELECT DISTINCT users.id, users.username
FROM suggestions
JOIN users ON users.id = suggestions.leader_id
WHERE depth > 1
LIMIT 30;
Views🔗
Ques : Find the most popular user ? A simple solution would be :
SELECT
FROM users
JOIN (
SELECT user_id FROM photo_tags
UNION ALL
SELECT user_id FROM caption_tags
) AS tags ON tags.user_id = users.id
GROUP BY username
ORDER BY COUNT(*) DESC;
To get to the answer of above query we are joining tables. But if we had to join tables too frequently it becomes inefficient to join tables again and again.
View is a like a fake table that wraps multiple tables together. We execute following query once ahead of time to avail views.
CREATE VIEW tags AS (
SELECT id, created_at, user_id, post_id, 'photo_tag' AS type FROM photo_tags
UNION ALL
SELECT id, created_at, user_id, post_id, 'captions_tag' AS type FROM captions_tags
);
Now we use the above created view :
Updating and Deleting Views🔗
Materialized Views🔗
More formally Views are queries that gets executed every time you refer to it and Materialised Views are queries that gets executed at very specific times, but results are saved and can be referenced without rerunning the query.
Reason why we use Materialised Views is because it saves time when Views are expensive since results are saved.
Ques : For each week, show the number of likes that posts and comments recieved. Use the post and comment created_at, not when the like was received.
SELECT
date_trunc('week',COALESCE(posts.created_at, comments.created_at)) AS week,
COUNT(posts.id) AS num_posts,
COUNT(comments.id) AS num_comments
FROM likes
LEFT JOIN posts ON posts.id = likes.post_id
LEFT JOIN comments ON comments.id = likes.comment_id
GROUP BY week
ORDER BY week;
Running above query takes a lots of time to execute, and if we run it again and again it will be slow to do more operation on views created. Materialized views helps caching the results of the query.
CREATE MATERIALIZED VIEW weekly_likes AS (
SELECT
date_trunc('week',COALESCE(posts.created_at, comments.created_at)) AS week,
COUNT(posts.id) AS num_posts,
COUNT(comments.id) AS num_comments
FROM likes
LEFT JOIN posts ON posts.id = likes.post_id
LEFT JOIN comments ON comments.id = likes.comment_id
GROUP BY week
ORDER BY week;
) WITH DATA;
Handling Concurrency and Reversibility with Transaction🔗
Transactions🔗
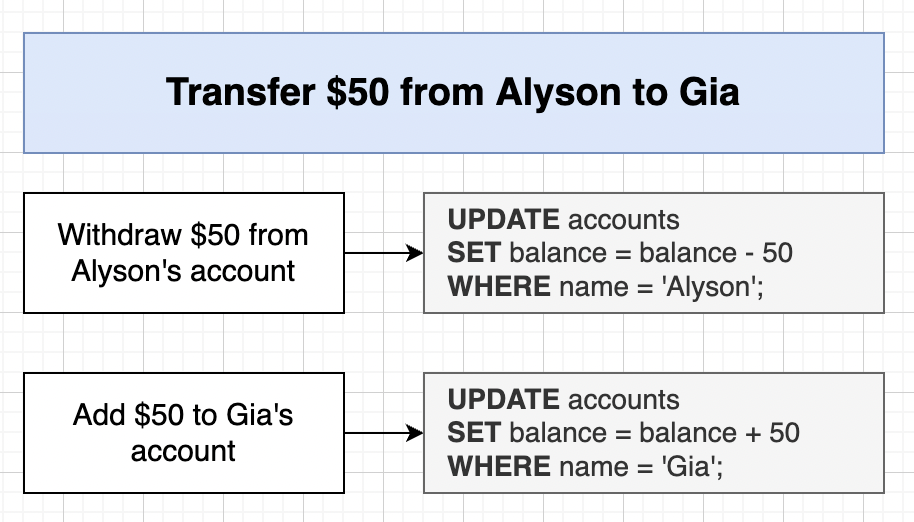
If server crashes happen after the first step has completed then 50$ is lost in the system. So transaction ensure that either the entire process completes sucessfully or nothing changes.
To start transaction block start queries with BEGIN keyword.
Now what transaction does typically is create a virtual workspace kind of system where while executing queries if there is a error or mistake system will go in abort state and we will need to execute ROLLBACK, you can execute ROLLBACK yourself even though there is no error to revert current transaction block. After making intended queries execute COMMIT to make the changes permanent.
NOTE : while you are in transaction blocks and whatever changes you are making will not be reflected in the database until you commit changes. So if there is another client connected to database he will not see any updates.
-- Beginning of transaction block
BEGIN;
UPDATE accounts
SET balance = balance-50
WHERE name = 'Alyson';
-- if there is an error system will go in abort state
-- system will not respond to queries until ROLLBACK is passed
-- ROLLBACK will end the current transaction block
COMMIT; -- makes changes permanent
Managing Database Design with Schema Migrations🔗
Schema Migration is all about changes structure of database.
Let’s say you are working an environment where making changes to the database breaks the applications running on that database i.e. lets say API. In that case if you want to share some updates to API as well as Database through a commit such that it won’t break the application. We use migration files that can be used by the person reviewing your requests for merge. They can easily change their database locally and updates to API you made and then revert back changes if they don’t like the commit or else accept the PR.
Migration Files : have two components UP (contains upgrades to structures of DB) and DOWN (undo whatever UP does).
Issues solved by Migration Files
- Changes to DB Structures and changes to clients need to be made at precisely the same time
- When working with other engineers, we need a really easy way to tie the structure of our database to our code.
Schema Migration Libraries are available almost in every language. Always write your own Migrations rather than using automatic migration provided with language.
/* eslint-disable camelcase */
exports.shorthands = undefined;
exports.up = pgm => {
pgm.sql(`
CREATE TABLE "comments" (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT NOW(),
updated_at TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT NOW(),
content VARCHAR(255) NOT NULL
);
`);
};
exports.down = pgm => {
pgm.sql(`
DROP TABLE "comments";
`);
};
SETUP Database_URL, NOTE : it varies if used in different Operating System, also remember to make database beforehand.
Then run following command :
More example of renaming a column
/* eslint-disable camelcase */
exports.shorthands = undefined;
exports.up = pgm => {
pgm.sql(`
ALTER TABLE "comments"
RENAME COLUMN "contents" TO "body";
`);
};
exports.down = pgm => {
pgm.sql(`
ALTER TABLE "comments"
RENAME COLUMN "body" TO "contents";
`);
};
Schema vs Data Migrations🔗
Task : Remove x,y or lat/lng columns and create a new column with name loc and data type point.
We will split the process in mainly 3 steps :
- Creating a new column called as loc with type point
- Copy lat/lng to the loc
- Drop the lat/lng column
Probably we should use transactions to make sure that above process happens completely.
Now lets assume there is API server POSTing data in real time :) . You transaction blocks won’t take them in consideration and we will have error or nulls.
Ideal process will be :
- Add column loc
- Deploy new Version of API that will write values to both lat/lng and loc
- Copy lat/lng to loc
- Update code to only write to loc column
- Drop columns lat/lng
Transaction Locks
If one transaction has locked a row then another transaction can’t access it to update. But if transaction number is one is quite large then other transaction/updates will need to wait for it to finish. These transaction/updates will not terminate or error out they will just wait forever until either the first transaction is rolled back or committed.
Accessing PostgreSQL from API’s🔗
mkdir social-repo
cd social-repo
npm init -y
npm install dedent express jest node-pg-migrate nodemon pg pg-format supertest
Replace “test” from scripts in package.json to :
/* eslint-disable camelcase */
exports.shorthands = undefined;
exports.up = pgm => {
pgm.sql(`
CREATE TABLE users (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT NOW(),
updated_at TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT NOW(),
bio VARCHAR(400),
username VARCHAR(100) UNIQUE NOT NULL
);
`);
};
exports.down = pgm => {
pgm.sql('DROP TABLE users;');
};
NOTE : Create a database socialnetwork
To run migration : DATABASE_URL=postgres://smk@localhost:5432/socialnetwork npm run migrate up
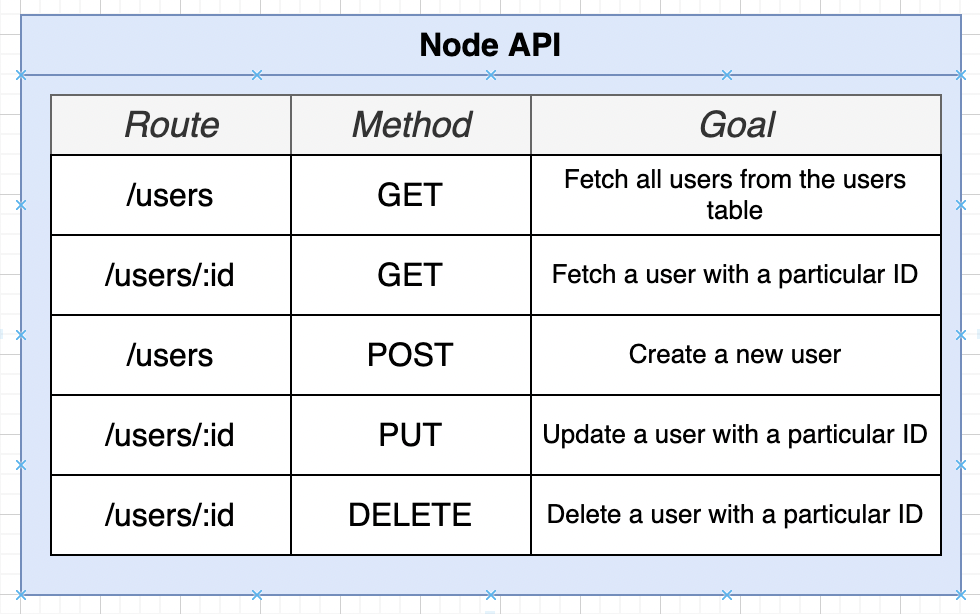
We will create a Node API
Create src/app.js
const express = require('express');
const usersRouter = require('./routes/users.js');
module.exports = () => {
const app = express();
app.use(express.json());
app.use(usersRouter);
return app;
};
Create a file src/routes/users.js
const express = require('express');
const router = express.Router();
router.get('/users', (req, res) => {});
router.get('/users/:id', (req, res) => {});
router.post('/users', (req, res) => {});
router.put('/users/:id', (req, res) => {});
router.delete('/users/:id', (req, res) => {});
module.exports = router;
PG module just creates a connection to Postgresql backend, PG is very famous Node package and underlying power of many packages.
PG maintains a pool instead of creating clients. A pool internally maintains several different clients that can be reused. You only need client when running transactions.
Create a new src/pool.js
const pg = require('pg');
class Pool {
_pool = null;
connect(callback) {
this._pool = new pg.Pool(callback);
return this._pool.query('SELECT 1 + 1;');
}
close() {
this._pool.end();
}
// big security issue here
query(sql) {
return this._pool.query(sql);
}
}
module.exports = new Pool;
Create a file index.js
const app = require('./src/app.js');
const pool = require('./src/pool.js');
pool.connect({
host: 'localhost',
user: 'smk',
port: 5432,
database: 'socialnetwork',
password: ''
})
.then(() => {
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
})
.catch(err => {
console.log(err);
});
Complete Code Available at Link
Security Issues around SQL🔗
SQL Injection
We never, ever directly concatenate user provided input into a sql query. There are a variety of safe ways to get user-provided values into a string.
There are 2 solution :
- Add code to ‘sanitize’ user-provided values to our app.
- Rely on Postgres to sanitize values for us.
Postgres create a prepared statement and executes the prepared statement. Use $1 variable for assigning values.